
In today’s digital world, images are everywhere. From social media and online shopping to medical scans and security cameras, millions of images are generated and shared every day. But have you ever wondered how apps like Google Photos recognize faces or how Flipkart shows you similar products based on a picture? The answer lies in a powerful technology called Image Classification using Deep Learning.
This article will take you through the basics of image classification, explain how deep learning is used in real-world scenarios, and present a case study that helps you understand how it all works. Whether you’re a student, a tech enthusiast, or someone looking to explore AI for career growth, this read will give you a valuable overview of the topic.
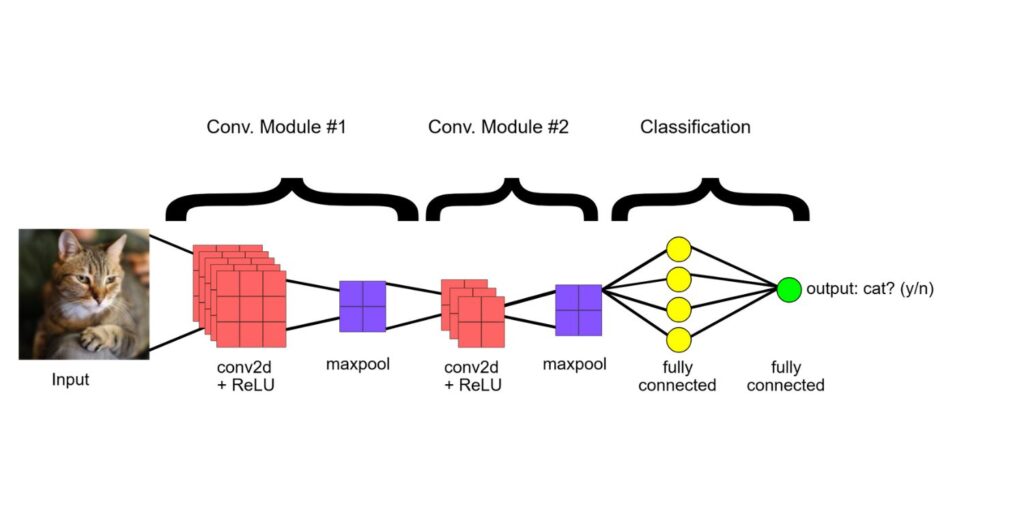
What is Image Classification?
Image classification is a type of task in computer vision where the goal is to assign a label or category to an image. For example, a system might look at a photo and decide whether it contains a dog, a cat, or a car. It sounds simple, but for a computer, understanding images like a human is a tough job.
Traditionally, image classification was done using feature extraction and machine learning algorithms like SVM or decision trees. However, with the rise of deep learning, especially Convolutional Neural Networks (CNNs), the accuracy and capability of these systems have grown significantly.
Why Deep Learning for Image Classification?
Deep learning is a branch of machine learning that uses algorithms inspired by how the human brain works. One of the main reasons deep learning works so well for image classification is because it can automatically learn features from raw images without manual intervention.
Convolutional Neural Networks (CNNs) are the backbone of deep learning in image tasks. They can detect edges, shapes, textures, and eventually complete objects by stacking multiple layers of processing. This helps in achieving human-level accuracy in tasks like object recognition and face detection.
Compared to traditional methods, deep learning models can handle complex images with different lighting, angles, and backgrounds. In India, where we have a wide range of real-world conditions—like blurry CCTV footage, crowded public places, and diverse clothing styles—deep learning provides a more robust solution.

Case Study: Identifying Indian Street Food Using Image Classification
Let’s take a fun and relatable example to understand how deep learning can be applied in a practical way. Suppose we want to build an app that can identify Indian street food items from photos. You take a picture of a plate of food, and the app tells you whether it’s samosa, vada pav, momos, or chole bhature.
This is how we can go about solving this using deep learning.
Step 1: Data Collection
First, we need to collect hundreds or thousands of images of each food item. For this, we can use online sources like Google Images, food blogs, or even take our own photos from local stalls. The more diverse our images are (different angles, lighting, backgrounds), the better our model will perform.
We’ll categorize them into folders—one for each type of food. For example:
- /samosa
- /vada_pav
- /momos
- /chole_bhature
Step 2: Preprocessing the Data
Once we have our dataset, we need to prepare it for training. This involves:
- Resizing all images to the same size (like 128×128 pixels)
- Converting them to arrays (numerical format)
- Normalizing pixel values (to make training faster and more accurate)
- Splitting the data into training and testing sets (usually 80% training and 20% testing)
We might also use techniques like data augmentation (flipping, rotating, zooming images) to increase the diversity of the dataset without collecting new images.
Step 3: Building the Deep Learning Model
Now comes the exciting part. We’ll use a Convolutional Neural Network (CNN) to build our model. A simple CNN might have the following layers:
- Convolutional layers to detect features
- Pooling layers to reduce size and complexity
- Fully connected layers to make predictions
- Activation functions like ReLU and Softmax for better learning and output
We can use Python libraries like TensorFlow or PyTorch to write this model. These are open-source and have strong communities in India, so it’s easy to find help and tutorials online.
Step 4: Training and Testing the Model
We train the model using our training images. During training, the model learns patterns in the images and adjusts itself to minimize error. This process can take a few minutes to several hours depending on the size of the data and hardware used.
Once trained, we test the model on the testing set to see how well it performs. We calculate accuracy, precision, and recall to evaluate the results. If the accuracy is low, we might need to collect more data or tweak the model.
Step 5: Deploying the Model
After achieving good performance, we can deploy the model in a mobile app or web application. The user takes a photo, the image is sent to our model, and it returns the name of the dish. We can even show nutritional information or suggest nearby stalls serving that dish.
Imagine how helpful this can be for tourists exploring Indian food or people with dietary restrictions trying to identify dishes!
Challenges and Solutions
Working with images in the real world comes with challenges:
- Background noise: Street food photos often have other items or people in the background.
- Low-quality images: Poor lighting or blurry shots can confuse the model.
- Class similarity: Some items like samosa and kachori look very similar.
To handle this, we can:
- Use advanced CNN models like ResNet or MobileNet for better accuracy.
- Fine-tune pre-trained models using transfer learning to save time.
- Continuously improve the dataset by adding new images over time.

Impact in the Indian Context
In India, image classification has huge potential across various sectors:
- Healthcare: Detecting diseases from X-rays and MRI scans
- Agriculture: Identifying crop diseases from leaf images
- Retail: Sorting products based on images for e-commerce
- Education: Building apps that help students learn through visual content
- Security: Recognizing faces in CCTV footage to enhance safety
With more startups and government initiatives promoting AI and digital solutions, now is the right time for Indian youth to explore careers in deep learning.
Conclusion: Why It Matters
Image classification using deep learning is not just a technical buzzword—it is a powerful tool that is changing the way we interact with the world. Whether it’s for fun projects like recognizing street food or serious applications like cancer detection, the opportunities are endless.
With free resources available online and communities that support learning, anyone with interest and dedication can get started. You don’t need a PhD or expensive equipment. Just curiosity, a laptop, and a willingness to learn.
